
Modern cellular operations increasingly combine higher-level service coordination with automated control of underlying elements. In practical terms, this approach aligns service requests, such as a new enterprise slice or mobile broadband instance, with configuration actions across radio access, transport, and core domains. The model emphasizes translating service intent into workflows that allocate resources, instantiate virtual or containerized network functions, and apply policy rules so that the delivered capability matches the requested service parameters.
Implementation typically involves layered control: a service orchestration layer that understands offerings and service catalogs, and lower layers that handle resource orchestration and element configuration. End-to-end automation links the initial service lifecycle — from design and onboarding through deployment — to ongoing operational tasks such as monitoring, scaling, and healing. In United States deployments, operators and systems integrators often coordinate these layers to meet regional regulatory and operational expectations.

Service orchestration often operates with a service catalog or intent model that describes available offerings and their parameters. In U.S. contexts, catalogs may reflect regional service mixes such as fixed wireless access, enterprise private networks, and mobile broadband slices. The orchestration layer typically maps a catalog item to workflows that provision resources across multiple domains; those workflows can be templated and parameterized so that deployments repeat with predictable configurations. Integration with operational data sources assists in validating that deployments match intent.
Resource orchestration and element management follow the service mapping. Resource orchestration coordinates compute, storage, and transport allocation across cloud and edge sites, which in the United States frequently involves public cloud regions or carrier-operated edge nodes. Element management systems apply device-level configurations for radio units, transport gear, and core functions. These layers may use adapters and southbound plugins to translate generic orchestration commands into vendor-specific APIs or command sequences.
Monitoring and assurance feed back into orchestration through automated workflows. Telemetry streams, fault logs, and performance metrics may trigger policy-driven actions such as scaling a CNF or rerouting traffic. In U.S. commercial settings, operators often the integrate telemetry platforms that can handle high-volume streams and provide role-based access for operations and security teams. Closed-loop patterns that connect assurance outputs to orchestration inputs are typically implemented cautiously and tested to avoid unintended configuration churn.
Standards and interoperability play a central role in multi-vendor U.S. environments. ETSI NFV concepts, 3GPP slice definitions, and open-source projects contribute reference models that operators and vendors map to proprietary implementations. Where open interfaces are used, integration effort may reduce; however, many U.S. deployments also require adapters or translation layers to connect legacy OSS/BSS systems. Emphasis on modular, API-first designs may help manage heterogeneity during integration and operations.
Security, compliance, and operational policy are integrated into orchestration flows as constraints and validation steps. In the United States, operators often incorporate regional regulatory requirements and industry guidance when defining service parameters and data handling rules. Authentication and authorization mechanisms, secure transport for telemetry, and audit trails for lifecycle changes are commonly part of orchestration design to support governance and incident response processes.
Overall, combining service-level orchestration with automation can streamline lifecycle tasks from provisioning to assurance while accommodating the complexity of multi-domain networks. In U.S. practice, pilot projects and phased rollouts often determine appropriate automation scope before scaling. The next sections examine practical components and considerations in more detail.
Service orchestration acts as the translator between a service description and domain-level actions that realize that service. In U.S. operator environments, orchestration roles commonly include catalog management, SLA constraint enforcement, and workflow coordination across radio, transport, and core domains. When network slicing is present, the orchestration layer may assign slice parameters such as isolation, latency, and throughput to underlying resources and request resource controllers to enforce those allocations. Mapping slice intents to concrete resource reservations often requires collaboration between orchestration and resource management components, and can involve per-slice policies to meet diverse enterprise or consumer needs.
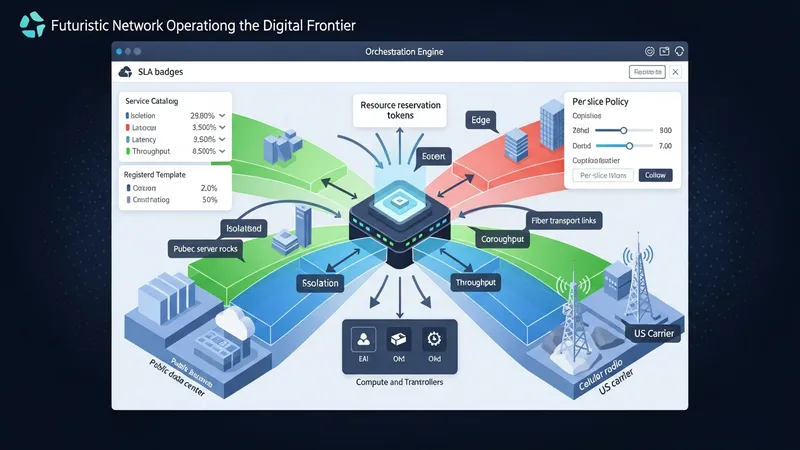
Practical mapping typically uses templates or intent models to reduce manual configuration. Registered templates in a U.S.-oriented service catalog may account for regional spectrum usage, edge site availability, and enterprise connectivity options. Orchestration systems can parameterize templates to reflect site-specific constraints and invoke resource orchestration to secure compute and transport capacity in targeted cloud or edge locations. Where service-level isolation is required, orchestration may coordinate virtual network functions and transport segmentation techniques used by U.S. carriers and infrastructure providers.
Interoperability considerations arise when slices traverse multi-vendor segments or partner domains. U.S. deployments that span carrier networks, public cloud providers, and third-party edge hosts often employ common data models or adapters to ensure consistent interpretation of slice parameters. Orchestration systems may implement translation layers to reconcile vendor-specific capabilities with standardized slice descriptors, reducing manual reconciliation during provisioning and simplifying lifecycle operations across disparate components.
Operationally, orchestration often includes validation and rollback steps that confirm resource allocations meet expected conditions before declaring a service active. In the United States, operators may run staged validations that verify radio coverage, transport latency, and compute readiness in edge sites. Automated rollbacks or remediation workflows are typically designed so that an unsuccessful provisioning attempt leaves the network in a known, safe state. This cautious approach supports predictable service activation across complex, multi-domain deployments.
Automation workflows define the sequence of tasks from service request through deployment and into steady-state operations. Common workflow stages include design-time validation, resource reservation, function instantiation, configuration, and post-deployment verification. In U.S. practice, toolchains often integrate CI/CD pipelines for network functions, enabling iterative updates and configuration management. These pipelines may use container registries, infrastructure-as-code tools, and orchestration APIs to manage deployments consistently across test, staging, and production environments.
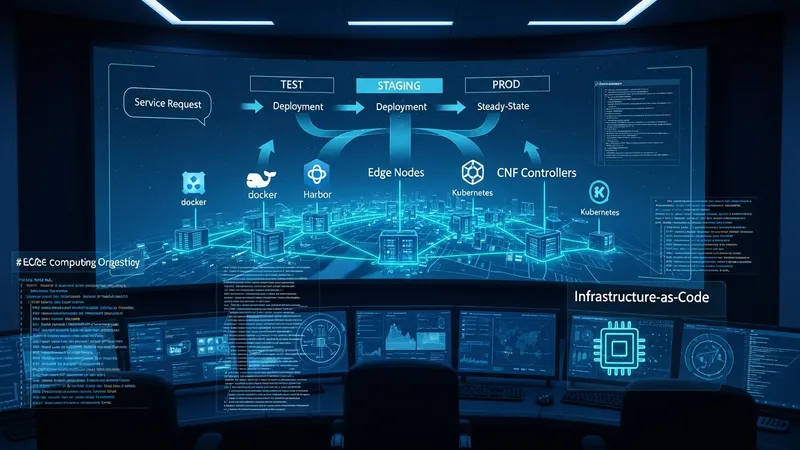
Tooling choices frequently blend open-source components with commercial platforms to meet scale and operational requirements. For example, Kubernetes distribution tailored for edge compute may be paired with network-specific controllers that handle CNF lifecycles. U.S. operators and systems integrators commonly use monitoring and logging stacks that support high-throughput telemetry and event correlation to feed automation triggers. Selecting tools that offer standard APIs and observable behaviors can simplify integration into broader operational processes.
Closed-loop automation patterns rely on assurance data to enact predefined remediation steps. In United States telemetry architectures, streaming platforms and time-series databases can provide near-real-time metrics that feed rule engines or ML-based classifiers. When anomalies are detected, workflows may initiate scaling actions, route adjustments, or configuration updates. Implementers typically design safeguards, such as rate limits and staged approvals, to prevent oscillation and unintended mass changes in production networks.
Lifecycle management often includes version control, rollback capability, and staged rollout strategies. U.S. deployments commonly adopt canary or progressive deployment methods to limit exposure during updates, with orchestration tooling coordinating traffic mirroring and gradual traffic shifts. Audit logs and change tracking are used to meet compliance and operational review needs, and these artifacts are frequently integrated into incident review processes so that automation-driven changes remain traceable and reviewable.
Effective monitoring supplies the data that powers assurance and closed-loop automation. Telemetry sources in U.S. networks typically include performance counters from radio units, flow and latency measurements on transport segments, and resource metrics from cloud and edge platforms. Aggregation and normalization of these telemetry streams enable consistent interpretation across domains; operators often deploy time-series databases and stream processing engines to support real-time analysis and historical trend assessments necessary for SLA verification and capacity planning.
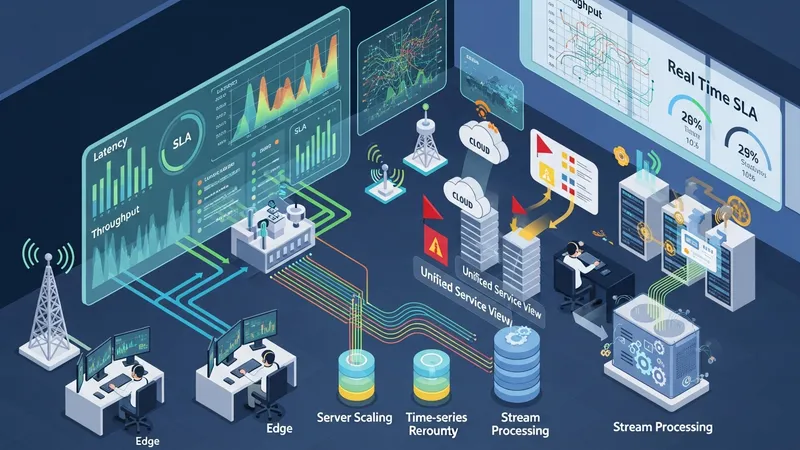
Assurance systems translate monitored indicators into service health assessments and alerts. In U.S. network operations centers, assurance dashboards may combine multi-domain indicators into a unified service view that correlates underlying resource states with service-level metrics. Automated rule sets and anomaly detection models can flag deviations from expected performance, and those detections may trigger orchestration workflows for remediation, such as scaling, rerouting, or reconfiguration of affected components.
Data volume and velocity pose practical challenges; U.S. deployments often handle large-scale telemetry by filtering, sampling, and tiering data to balance operational needs and storage costs. Edge aggregation points can pre-process telemetry to reduce upstream load, while longer-term storage may retain aggregated or summarized indicators for trend analysis. Careful design of telemetry schemas and retention policies helps ensure that assurance systems remain responsive and cost-manageable.
Privacy and security of telemetry are also operational considerations. In the United States, operators may follow sector guidance and internal policies for data handling, access control, and retention. Encryption in transit, role-based access to assurance tools, and auditability of automation triggers are commonly included as defensive measures. These controls help ensure that closed-loop actions rely on trusted data and that any automated changes remain accountable within operational governance frameworks.
Integrating orchestration into existing operational ecosystems often requires mapping to legacy OSS/BSS functions and procurement processes commonly used in the United States. Legacy systems may expose proprietary APIs or require batch interfaces, so integration efforts frequently include adapter layers and phased migration plans. Procurement and contractual arrangements with vendors and cloud providers can also affect automation architectures, with considerations for support boundaries, SLA terms, and integration timelines that influence deployment sequencing.

Policy and regulatory constraints in the United States influence design choices, particularly for public safety, lawful intercept, and spectrum use. Orchestration flows that affect traffic routing or allocate spectrum resources may need to incorporate compliance checks or predefined policy constraints. Operators commonly consult FCC guidance and industry best practices when defining automation policies that interact with regulated capabilities, and they may maintain audit trails to support regulatory reporting and incident investigations.
Cost factors relevant to U.S. deployments include capital and operational expenditures for compute and transport capacity, licensing or cloud consumption, and integration engineering. Automation can reduce manual operational effort but may also introduce upfront engineering and tooling costs. Typical U.S. planning cycles evaluate total cost of ownership over multi-year horizons and incorporate sensitivity analyses for traffic growth, edge site proliferation, and evolving service mixes to inform orchestration investment decisions.
Interoperability and vendor diversity remain practical considerations: U.S. operators often balance open interfaces with vendor-specific optimizations, and orchestration architectures are designed to accommodate both. Clear interface specifications, rigorous testing, and incremental onboarding of vendors or partners can help manage integration risk. As deployments mature, operators may expand automation scopes and refine policies, maintaining a cautious, data-driven approach to scale orchestration and end-to-end automation across their networks.